
上节我们介绍了ArrayList,ArrayList随机访问效率很高,但插入和删除性能比较低,我们提到了同样实现了List接口的LinkedList,它的特点与ArrayList几乎正好相反,本节我们就来详细介绍LinkedList。
除了实现了List接口外,LinkedList还实现了Deque和Queue接口,可以按照队列、栈和双端队列的方式进行操作,本节会介绍这些用法,同时介绍其实现原理。
我们先来看它的用法。
用法
构造方法
LinkedList的构造方法与ArrayList类似,有两个,一个是默认构造方法,另外一个可以接受一个已有的Collection,如下所示:
public LinkedList() public LinkedList(Collection<? extends E> c)
比如,可以这么创建:
List<String> list = new LinkedList<>();
List<String> list2 = new LinkedList<>(
Arrays.asList(new String[]{"a","b","c"}));
List接口
LinkedList与ArrayList一样,同样实现了List接口,而List接口扩展了Collection接口,Collection又扩展了Iterable接口,所有这些接口的方法都是可以使用的,使用方法与上节介绍的一样,本节就不再赘述了。
队列 (Queue)
LinkedList还实现了队列接口Queue,所谓队列就类似于日常生活中的各种排队,特点就是先进先出,在尾部添加元素,从头部删除元素,它的接口定义为:
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e);
E remove();
E poll();
E element();
E peek();
}
Queue扩展了Collection,它的主要操作有三个:
- 在尾部添加元素 (add, offer)
- 查看头部元素 (element, peek),返回头部元素,但不改变队列
- 删除头部元素 (remove, poll),返回头部元素,并且从队列中删除
每种操作都有两种形式,有什么区别呢?区别在于,对于特殊情况的处理不同。特殊情况是指,队列为空或者队列为满,为空容易理解,为满是指队列有长度大小限制,而且已经占满了。LinkedList的实现中,队列长度没有限制,但别的Queue的实现可能有。
在队列为空时,element和remove会抛出异常NoSuchElementException,而peek和poll返回特殊值null,在队列为满时,add会抛出异常IllegalStateException,而offer只是返回false。
把LinkedList当做Queue使用也很简单,比如,可以这样:
Queue<String> queue = new LinkedList<>();
queue.offer("a");
queue.offer("b");
queue.offer("c");
while(queue.peek()!=null){
System.out.println(queue.poll());
}
输出为:
a b c
栈
我们在介绍函数调用原理的时候介绍过栈,栈也是一种常用的数据结构,与队列相反,它的特点是先进后出、后进先出,类似于一个储物箱,放的时候是一件件往上放,拿的时候则只能从上面开始拿。
Java中有一个类Stack,用于表示栈,但这个类已经过时了,我们不再介绍,Java中没有单独的栈接口,栈相关方法包括在了表示双端队列的接口Deque中,主要有三个方法:
void push(E e); E pop(); E peek();
解释下:
- push表示入栈,在头部添加元素,栈的空间可能是有限的,如果栈满了,push会抛出异常IllegalStateException。
- pop表示出栈,返回头部元素,并且从栈中删除,如果栈为空,会抛出异常NoSuchElementException。
- peek查看栈头部元素,不修改栈,如果栈为空,返回null。
把LinkedList当做栈使用也很简单,比如,可以这样:
Deque<String> stack = new LinkedList<>();
stack.push("a");
stack.push("b");
stack.push("c");
while(stack.peek()!=null){
System.out.println(stack.pop());
}
输出为:
c b a
双端队列 (Deque)
栈和队列都是在两端进行操作,栈只操作头部,队列两端都操作,但尾部只添加、头部只查看和删除,有一个更为通用的操作两端的接口Deque,Deque扩展了Queue,包括了栈的操作方法,此外,它还有如下更为明确的操作两端的方法:
void addFirst(E e); void addLast(E e); E getFirst(); E getLast(); boolean offerFirst(E e); boolean offerLast(E e); E peekFirst(); E peekLast(); E pollFirst(); E pollLast(); E removeFirst(); E removeLast();
xxxFirst操作头部,xxxLast操作尾部。与队列类似,每种操作有两种形式,区别也是在队列为空或满时,处理不同。为空时,getXXX/removeXXX会抛出异常,而peekXXX/pollXXX会返回null。队列满时,addXXX会抛出异常,offerXXX只是返回false。
栈和队列只是双端队列的特殊情况,它们的方法都可以使用双端队列的方法替代,不过,使用不同的名称和方法,概念上更为清晰。
Deque接口还有一个迭代器方法,可以从后往前遍历
Iterator<E> descendingIterator();
比如,看如下代码:
Deque<String> deque = new LinkedList<>(
Arrays.asList(new String[]{"a","b","c"}));
Iterator<String> it = deque.descendingIterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
输出为
c b a
用法小结
LinkedList的用法是比较简单的,与ArrayList用法类似,支持List接口,只是,LinkedList增加了一个接口Deque,可以把它看做队列、栈、双端队列,方便的在两端进行操作。
如果只是用作List,那应该用ArrayList还是LinkedList呢?我们需要了解下LinkedList的实现原理。
实现原理
内部组成
我们知道,ArrayList内部是数组,元素在内存是连续存放的,但LinkedList不是。LinkedList直译就是链表,确切的说,它的内部实现是双向链表,每个元素在内存都是单独存放的,元素之间通过链接连在一起,类似于小朋友之间手拉手一样。
为了表示链接关系,需要一个节点的概念,节点包括实际的元素,但同时有两个链接,分别指向前一个节点(前驱)和后一个节点(后继),节点是一个内部类,具体定义为:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node类表示节点,item指向实际的元素,next指向下一个节点,prev指向前一个节点。
LinkedList内部组成就是如下三个实例变量:
transient int size = 0; transient Node<E> first; transient Node<E> last;
我们暂时忽略transient关键字,size表示链表长度,默认为0,first指向头节点,last指向尾节点,初始值都为null。
LinkedList的所有public方法内部操作的都是这三个实例变量,具体是怎么操作的?链接关系是如何维护的?我们看一些主要的方法,先来看add方法。
Add方法
add方法的代码为:
public boolean add(E e) {
linkLast(e);
return true;
}
主要就是调用了linkLast,它的代码为:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
代码的基本步骤是:
1. 创建一个新的节点newNode。prev指向原来的尾节点,如果原来链表为空,则为null。代码为:
Node<E> newNode = new Node<>(l, e, null);
2. 修改尾节点last,指向新的最后节点newNode。代码为:
last = newNode;
3. 修改前节点的后向链接,如果原来链表为空,则让头节点指向新节点,否则让前一个节点的next指向新节点。代码为:
if (l == null)
first = newNode;
else
l.next = newNode;
4. 增加链表大小。代码为:
size++
modCount++的目的与ArrayList是一样的,记录修改次数,便于迭代中间检测结构性变化。
我们通过一些图示来更清楚的看一下,比如说,代码为:
List<String> list = new LinkedList<String>();
list.add("a");
list.add("b");
执行完第一行后,内部结构如下所示:

添加完"a"后,内部结构如下所示:
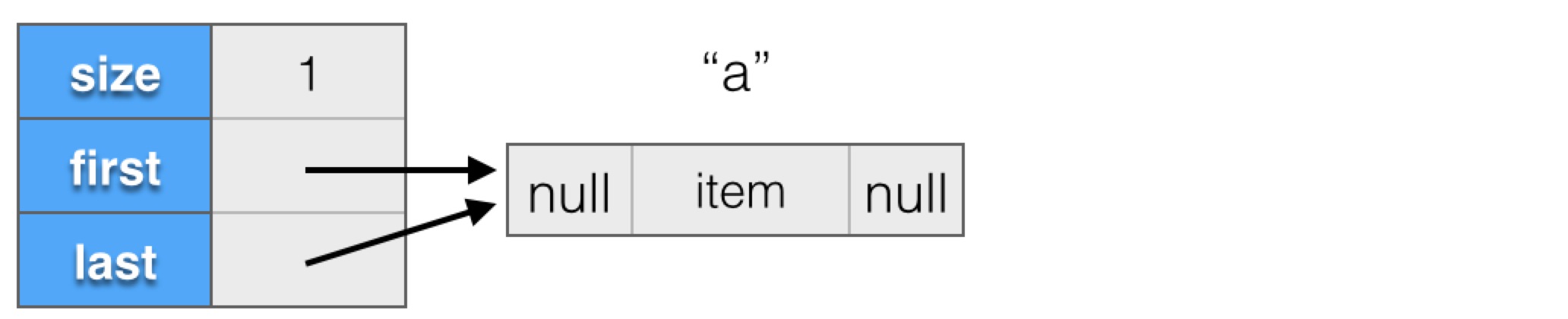
添加完"b"后,内部结构如下所示:

可以看出,与ArrayList不同,LinkedList的内存是按需分配的,不需要预先分配多余的内存,添加元素只需分配新元素的空间,然后调节几个链接即可。
根据索引访问元素 get
添加了元素,如果根据索引访问元素呢?我们看下get方法的代码:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
checkElementIndex检查索引位置的有效性,如果无效,抛出异常,代码为:
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
如果index有效,则调用node方法查找对应的节点,其item属性就指向实际元素内容,node方法的代码为:
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
size>>1等于size/2,如果索引位置在前半部分 (index<(size>>1)),则从头节点开始查找,否则,从尾节点开始查找。
可以看出,与ArrayList明显不同,ArrayList中数组元素连续存放,可以直接随机访问,而在LinkedList中,则必须从头或尾,顺着链接查找,效率比较低。
根据内容查找元素
我们看下indexOf的代码:
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
代码也很简单,从头节点顺着链接往后找,如果要找的是null,则找第一个item为null的节点,否则使用equals方法进行比较。
插入元素
add是在尾部添加元素,如果在头部或中间插入元素呢?可以使用如下方法:
public void add(int index, E element)
它的代码是:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
如果index为size,添加到最后面,一般情况,是插入到index对应节点的前面,调用方法为linkBefore,它的代码为:
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
参数succ表示后继节点。变量pred就表示前驱节点。目标就是在pred和succ中间插入一个节点。插入步骤是:
1. 新建一个节点newNode,前驱为pred,后继为succ。代码为:
Node<E> newNode = new Node<>(pred, e, succ);
2. 让后继的前驱指向新节点。代码为:
succ.prev = newNode;
3. 让前驱的后继指向新节点,如果前驱为空,修改头节点指向新节点。代码为:
if (pred == null)
first = newNode;
else
pred.next = newNode;
4. 增加长度。
我们通过图示来更清楚的看下,还是上面的例子,比如,添加一个元素:
list.add(1, "c");
图示结构会变为:
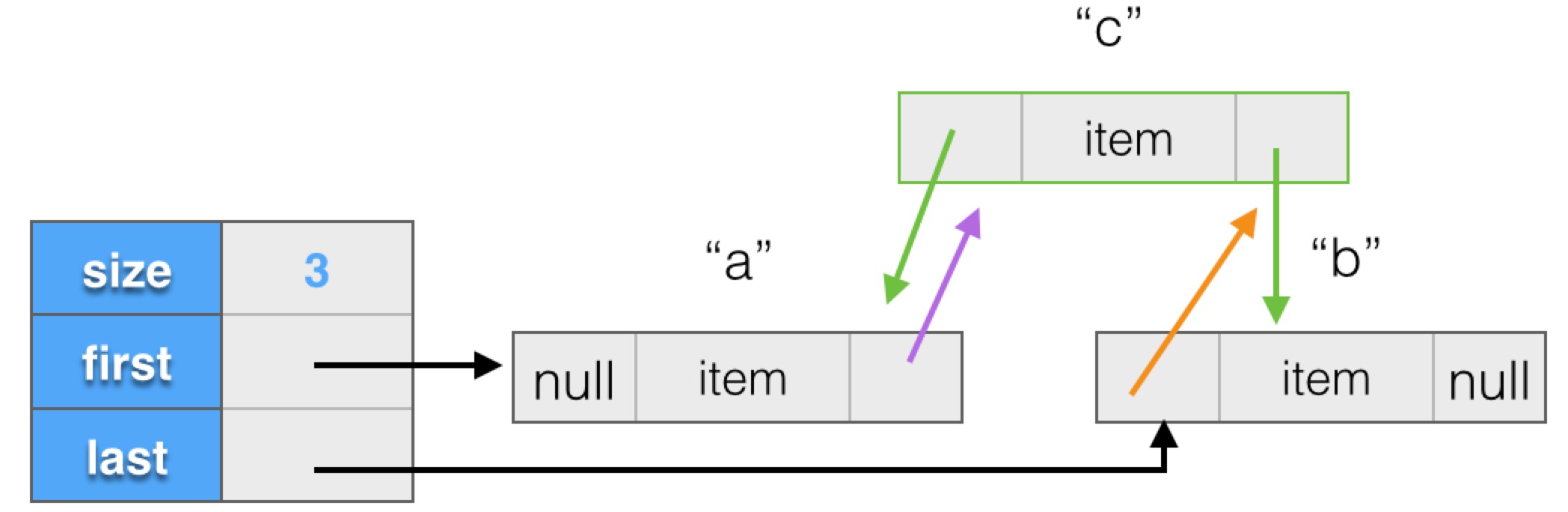
可以看出,在中间插入元素,LinkedList只需按需分配内存,修改前驱和后继节点的链接,而ArrayList则可能需要分配很多额外空间,且移动所有后续元素。
删除元素
我们再来看删除元素,代码为:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
通过node方法找到节点后,调用了unlink方法,代码为:
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
删除x节点,基本思路就是让x的前驱和后继直接链接起来,next是x的后继,prev是x的前驱,具体分为两步:
- 第一步是让x的前驱的后继指向x的后继。如果x没有前驱,说明删除的是头节点,则修改头节点指向x的后继。
- 第二步是让x的后继的前驱指向x的前驱。如果x没有后继,说明删除的是尾节点,则修改尾节点指向x的前驱。
我们再通过图示看下,还是上面的例子,如果删除一个元素:
list.remove(1);
图示结构会变为:

原理小结
以上,我们介绍了LinkedList的内部组成,以及几个主要方法的实现代码,其他方法的原理也都类似,我们就不赘述了。
前面我们提到,对于队列、栈和双端队列接口,长度可能有限制,LinkedList实现了这些接口,不过LinkedList对长度并没有限制。
LinkedList特点分析
LinkedList内部是用双向链表实现的,维护了长度、头节点和尾节点,这决定了它有如下特点:
- 按需分配空间,不需要预先分配很多空间
- 不可以随机访问,按照索引位置访问效率比较低,必须从头或尾顺着链接找,效率为O(N/2)。
- 不管列表是否已排序,只要是按照内容查找元素,效率都比较低,必须逐个比较,效率为O(N)。
- 在两端添加、删除元素的效率很高,为O(1)。
- 在中间插入、删除元素,要先定位,效率比较低,为O(N),但修改本身的效率很高,效率为O(1)。
理解了LinkedList和ArrayList的特点,我们就能比较容易的进行选择了,如果列表长度未知,添加、删除操作比较多,尤其经常从两端进行操作,而按照索引位置访问相对比较少,则LinkedList就是比较理想的选择。
小结
本节详细介绍了LinkedList,先介绍了用法,然后介绍了实现原理,最后我们分析了LinkedList的特点,并与ArrayList进行了比较。
用法上,LinkedList是一个List,但也实现了Deque接口,可以作为队列、栈和双端队列使用。实现原理上,内部是一个双向链表,并维护了长度、头节点和尾节点。
无论是ArrayList还是LinkedList,按内容查找元素的效率都很低,都需要逐个进行比较,有没有更有效的方式呢?




发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。