参见 HDP2.4安装(五):集群及组件安装 ,安装配置的spark版本为1.6, 在已安装hbase、hadoop集群的基础上通过 ambari 自动安装Spark集群,基于hadoop yarn 的运行模式。
目录:
- Spark集群安装
- 参数配置
- 测试验证
Spark集群安装:
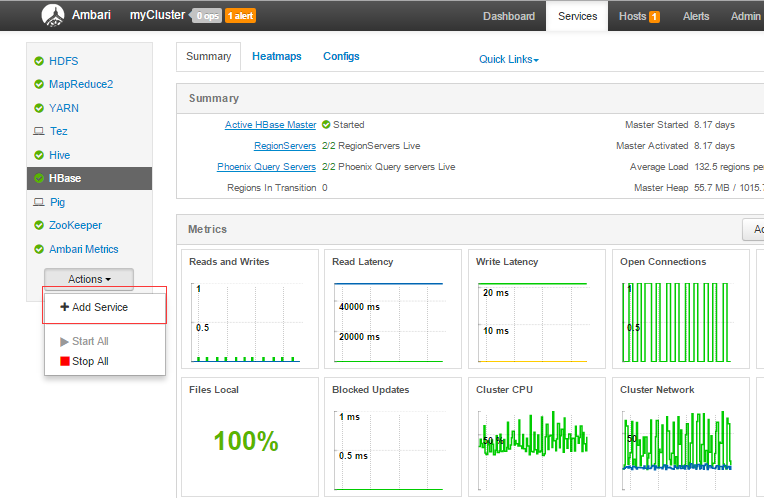
- 在ambari -service 界面选择 “add Service”,如图:
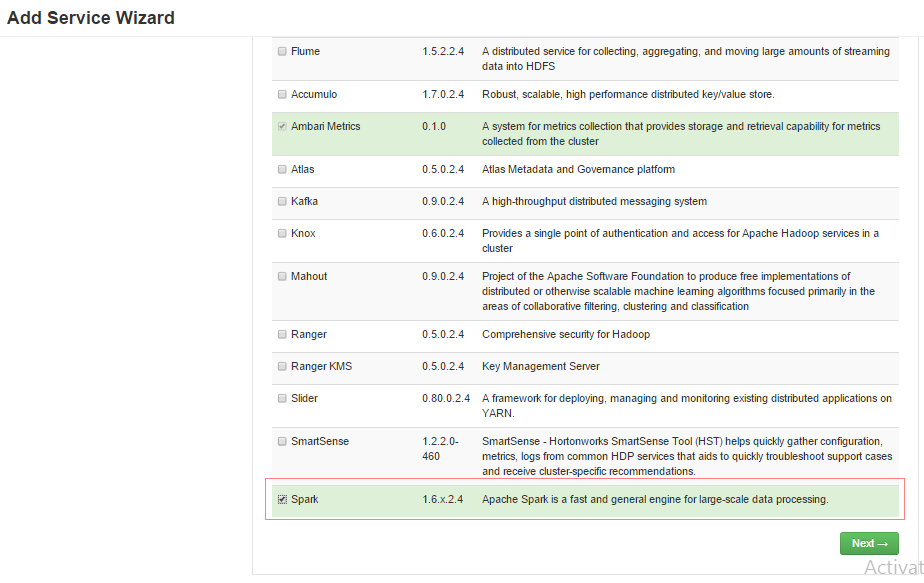
- 在弹出界面选中spark服务,如图:
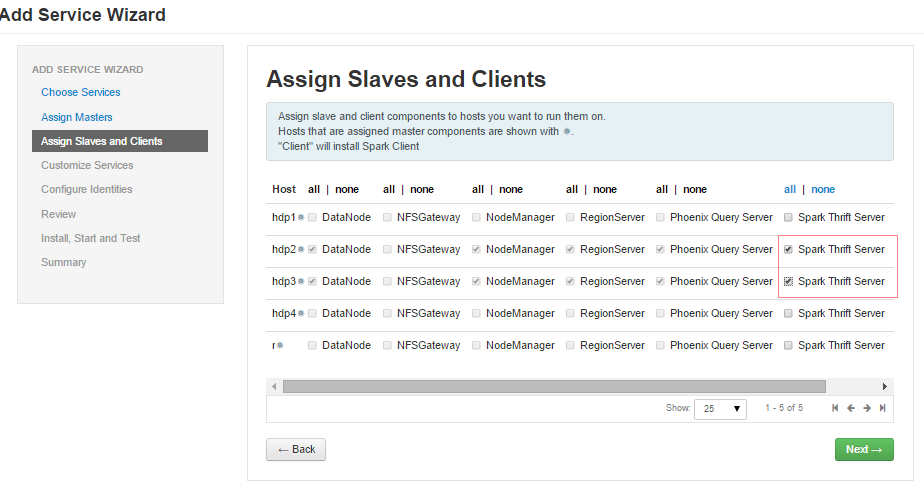
- “下一步”,分配host节点,因为前期我们已经安装了hadoop 和hbase集群,按向导分配 spark history Server即可
- 分配client,如下图:
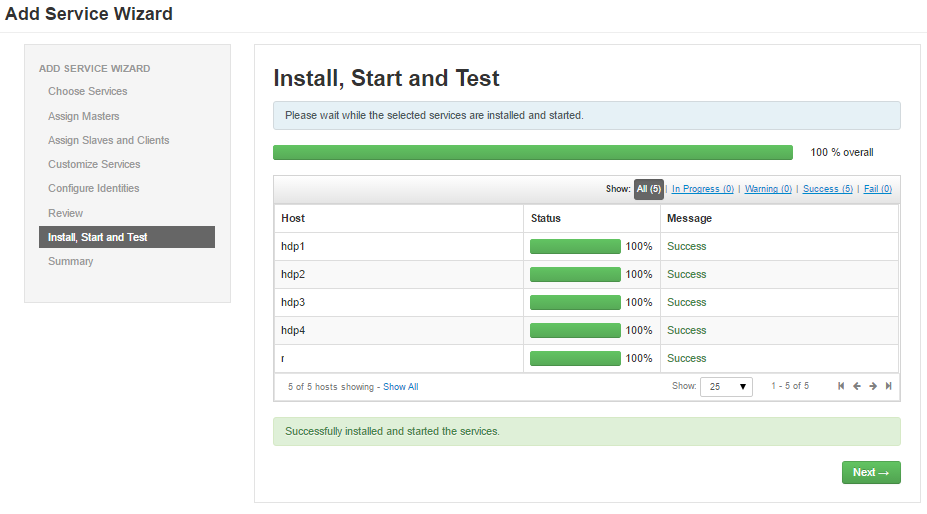
- 发布安装,如下正确状态
参数配置:
- 安装完成后,重启hdfs 和 yarn
- 查看 spark服务,spark thrift server 未正常启动,日志如下:


16/08/30 14:13:25 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (512 MB per container) 16/08/30 14:13:25 ERROR SparkContext: Error initializing SparkContext. Java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the max threshold (512 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'. at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:284) at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:140) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:56) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:144) at org.apache.spark.SparkContext.<init>(SparkContext.scala:530) at org.apache.spark.sql.hive.thriftserver.SparkSqlEnv$.init(SparkSQLEnv.scala:56) at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:76) at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731) at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181) at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。